
Optical Character Recognition (OCR) with PEERNET

We here at PEERNET are thrilled to announce the addition of Optical Character Recognition (OCR) to our family of virtual printer drivers: TIFF Image Printer, Raster Image Printer, and PDF Image Printer.
Say hello to dynamic, searchable PDF files and editable text files from images.
Images traditionally presented a challenge when you needed to extract the text. With optical character recognition, our printers can transform images into searchable documents. Your printed and scanned documents can effortlessly become searchable PDF files or editable hOCR, text, and ALTO files you can search, organize, and integrate into your business workflow.
What is Optical Character Recognition (OCR)?
First, what is Optical Character Recognition, or OCR? Also, what exactly happens when you OCR a PDF or an image?
OCR examines the image using pattern recognition and artificial intelligence. It looks for patterns, shapes, and spacing that resemble text characters, lines, and paragraphs. It matches the shapes against predefined patterns for each language chosen to recognize. Each character match is assigned a confidence level or score. The highest score determines which character in which language matches.
As part of the recognition process, optical character recognition also identifies and stores information about the layout and formatting of the text on the image.
Using this information, we can create searchable PDF files. Or, if we are creating TIFF, JPEG, or other images, we can bundle the text and layout information with the corresponding image for document management systems to make images searchable.
Other uses for this information are in archives to convert printed material into a digital format, by researchers for data mining and text analysis, and by accessibility tools.
Searchable PDF Files Using Optical Character Recognition
A searchable PDF file is one where you can search for and locate text on the page. You can select the text on the page and, if allowed, copy and paste it into other documents.
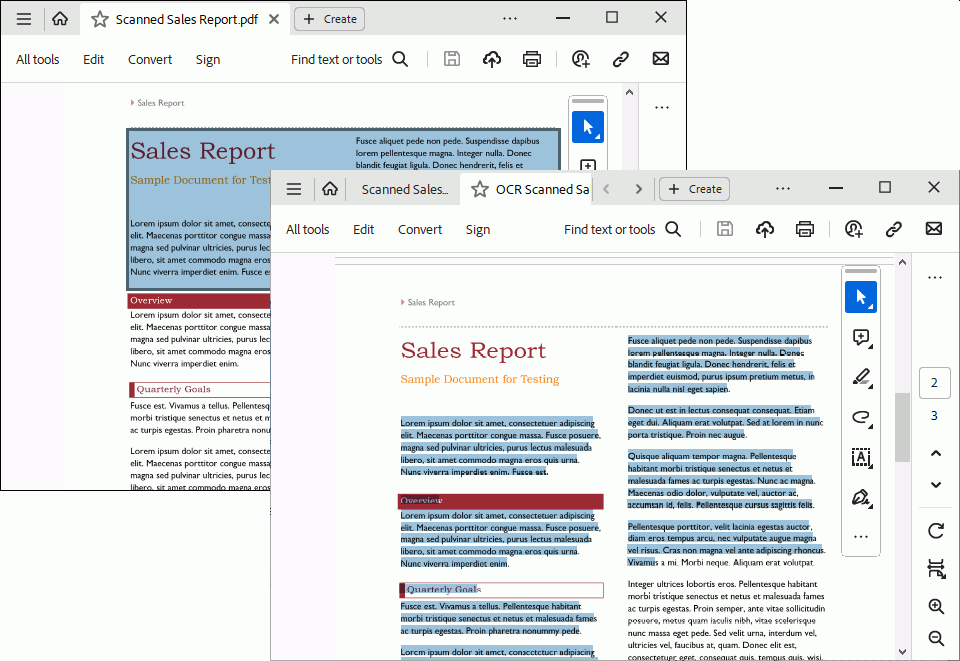
Scanned PDF documents are often just images of each page wrapped as a PDF file. You cannot search or copy the text in these files. The easiest way to tell if a page is a scanned image is to try and select the text. If it is an image, you cannot select any text on the page, only an area of the page, as shown here.
When you print a scanned PDF file to our printers, OCR will add the text on the pages as an invisible layer you can search and copy.
Optical character recognition is not just for PDF files. Print and append images together to convert images into a searchable PDF. You can make the images in a PDF searchable, just like the text. Printing a PDF containing text and pictures creates a new PDF where the original text and text in pictures are now searchable.
Do you already have a scanned PDF you want to make searchable? Follow our quick steps in Convert PDF to Searchable PDF with OCR to see how easy it is.
Optical Character Recognition Can Extract Text From Images
When creating TIFF, PNG, JPEG, and other images using the TIFF Image Printer and Raster Image Printer, you use the optical character recognition feature to extract the text to digital hOCR, text, and ALTO files. There is no way to embed the text information into an image the way you can with a PDF.
hOCR is a specially formatted XHTML file containing the text extracted from the page. It stores format and layout information and a score for how confident the OCR engine is on its match.
An ALTO file is similar to hOCR but stores the information using a different structure and specification.
Both formats contain human-readable text extracted from the image and work with different OCR tools and applications.
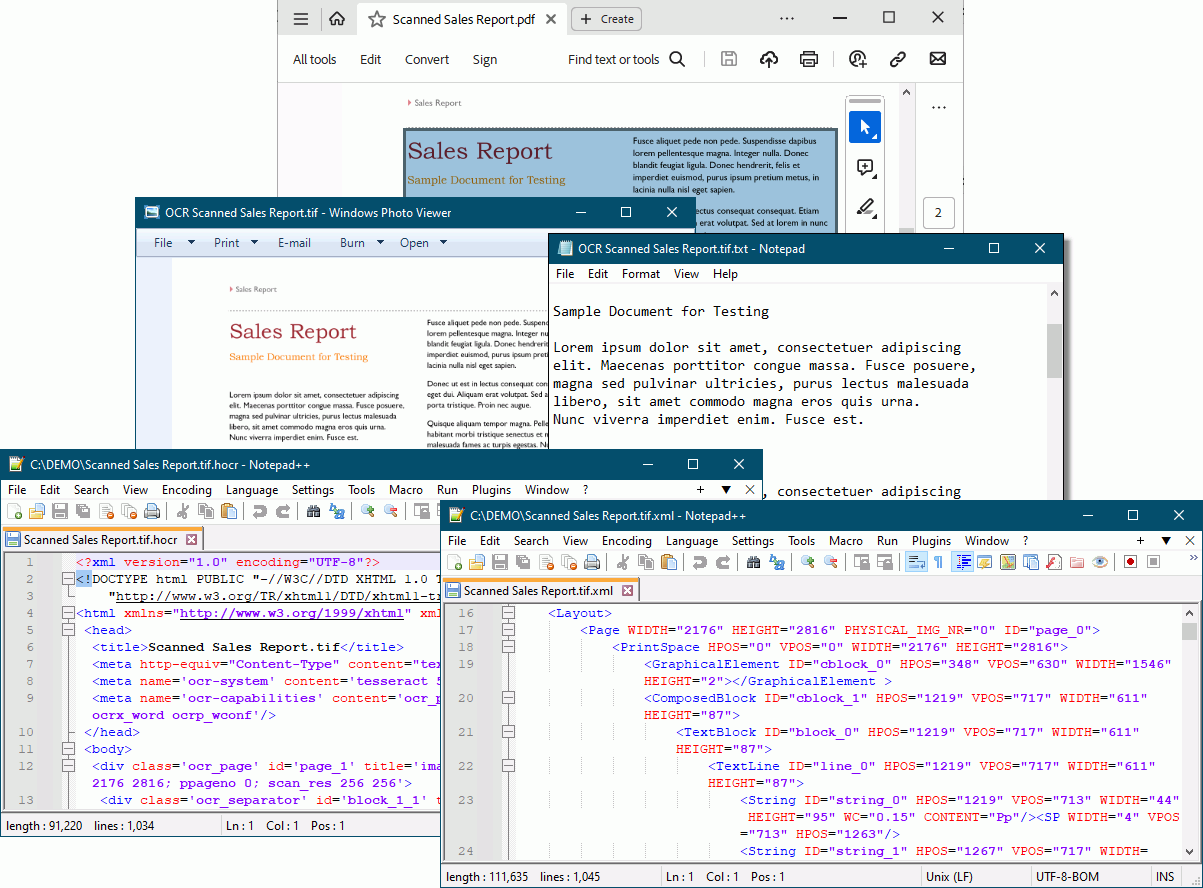
A text file, however, contains only the text extracted from the image. It does not attempt to mimic the layout of the text on the image. This file contains only plain, human-readable, and editable text that you can edit in any text editor.
This format is perfect when you need to copy the text from the image into another document. You can also use it to perform text recognition on the image as part of a document archiving step.
Our tutorial, Create TIFF and Extract Text From Images Using OCR, shows how easy it is to extract text from images in a single step.
Recognizing Different Languages
Our optical character recognition uses one or more language datasets to match the shapes and curves on the page to text characters.
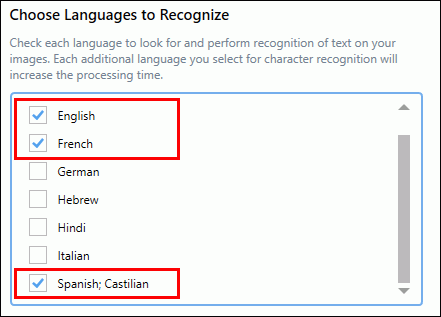
We recognize and match shapes against the English language dataset to start. The installation also includes the French, Italian, German, Spanish, Arabic, Hebrew, and Hindu language datasets.
You control which languages to look for when performing optical character recognition. The best practice is to check only the languages you know are in your document. The more languages to test, the longer the process takes.
Need other languages? No problem. There are over 100 language datasets you can download and add. You’re sure to find the language you need.
Ready to Try It?
Adding optical character recognition to our virtual printers marks a significant milestone in our commitment to providing solutions to our users. We’re excited to be able to offer this feature to you. We hope you will join us as we enter into the world of OCR and explore the world of possibilities it unlocks.
Download a trial of PDF Image Printer, Raster Image Printer, or TIFF Image Printer and try it out today! Already own one of our image printers? Log in to your online account to download the latest version and see what OCR can do.

