The OCR tab holds all settings for performing optical character recognition in PDF files, scanned documents, and images.
Optical character recognition, or OCR for short, attempts to recognize the text, or characters, on scanned pages or images and extract it as digital text. When performing OCR on a page, the OCR engine needs to know which languages you want to look for on the page. It does not automatically detect what language the characters are.
With the list of the target languages, the engine will attempt to recognize a character, text, or field on the page against each chosen language and assign a confidence score for each. A confidence score is how likely the OCR engine has correctly recognized the text. The language with the highest confidence score determines the text. Outside factors such as image quality, the font used, and any image background all affect the validity of the OCR results.
When OCR is enabled, this digital text is added to PDF files containing scanned images to create searchable PDF files. You can also save the OCR results externally as hOCR (.hocr), text (.txt), and ALTO (.xml) files. These files are saved in the same directory and with the same base name as the output PDF.
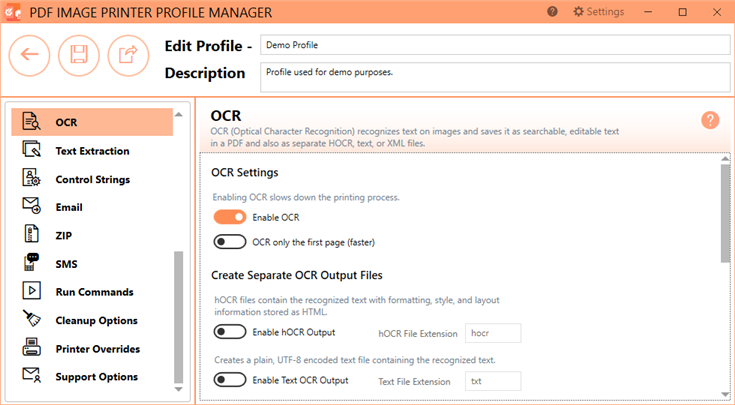
Enable OCR
This setting is disabled to start. Enable this setting to have PDF Image Printer run OCR on your printed pages. Running OCR does slow down the conversion process.
OCR only the first page
Enable this to have PDF Image Printer run OCR only on the first printed page. Only searching the first page speeds up the OCR process when you only need the information on the first page.
Create Separate OCR Output Files
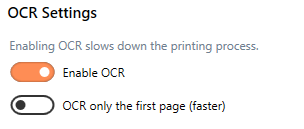
When creating a PDF file with OCR enabled, the OCR text gets embedded into the PDF file, creating a searchable PDF from scanned pages and images. You can also save recognized text from the OCR process as one or more of three different output formats for further processing and examination. These external files are created in the same directory and with the same base name as the output file.
hOCR Output
Enable this to create hOCR files. These files are human-readable OCR files. They contain the recognized text, formatting and layout information, and confidence scores from the OCR process. Saved as XHTML, an hOCR file is a standardized format for making digital files searchable.
hOCR File Extension
The default file extension for hOCR files is hocr. You can change this if needed.
Text OCR Output
Creates a UTF-8 encoded text file that contains the recognized text. No formatting or confidence levels are stored.
If you have Text Extraction enabled, and enable this option, an error will be shown as both features will try to write to the same file when using the default extension of txt for OCR. You can either turn off Text Extraction or change the OCR text output extension to prevent errors trying to write to the same file name.
Text File Extension
The default file extension for text OCR files is txt. You can change this if needed.
ALTO Output
Analyzed Layout and Text Object, or ALTO format, is an XML-formatted file that contains information about the page and text layout. It stores the recognized text and information about its position on the page.
ALTO File Extension
The default file extension for ALTO OCR files is xml as it is an XML-formatted document. You can change this if needed.
Choose Languages to Recognize
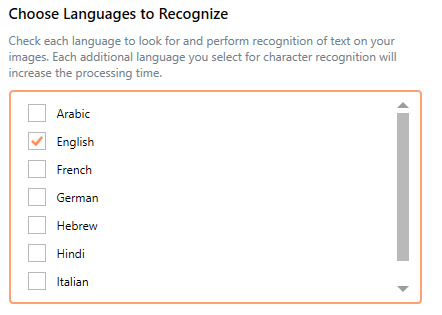
Select from the list which languages to recognize on the page. English is preselected by default. You must have at least one language selected for OCR.
The OCR process cannot automatically determine what language a character on the page is from. It needs to know what to try and match against. If you have a mix of English and Spanish on your page, you must check both English and Spanish from the list. If you have documents in English, French, and German, you must check English, French, and German.
The more languages selected from the list, the longer the OCR process will take as it validates the text against each language.
When running OCR over the text on the page, how well each character matches each language is assigned a confidence level. When recognizing text against multiple languages, the language with the highest confidence level determines which language matches.
Adding Languages
PDF Image Printer comes with language files for the following languages:
•Arabic
•English
•French
•German
•Hebrew
•Hindi
•Italian
•Spanish
You can download additional language files or complete sets of language files from Traineddata Files for Tesseract.
To add them to PDF Image Printer, copy the desired *.traineddata files into the following folder:
%PROGRAMDATA%\PEERNET Inc\PDF Image Printer\tessdata
To refresh the language list on this tab, select a different option from the list on the left-hand side and then return to the OCR options tab.
See Also: Use OCR to Create Searchable PDF Files